
บทความนี้ใช้หุ่นยนต์เขียน
-
 01 Oct 2018
01 Oct 2018
-
 104501
104501
“Despite these astonishing advances, we are a long way from machines that are as intelligent as humans - or even rats. So far, we’ve seen only 5% of what AI can do
แม้เราจะได้เห็นความก้าวหน้าที่น่าทึ่งหลายอย่าง แต่เครื่องคอมพิวเตอร์ที่ฉลาดเท่ามนุษย์หรือแม้แต่ฉลาดเท่าหนูนั้นก็ยังเป็นเรื่องที่ไกลจากความจริงนัก ตอนนี้เราได้เห็นศักยภาพของปัญญาประดิษฐ์เพียงแค่ 5 เปอร์เซ็นต์ เท่านั้น”
Yann LeCun ผู้อำนวยการด้านวิจัย บริษัทเฟซบุ๊ก
กระแสข่าวตอนนี้หลายคนคงได้ยินว่าปัญญาประดิษฐ์ (Artificial Intellgence หรือ AI) นั้นจะฉลาดจนเข้ามาปั่นป่วนเขมือบทุกวงการ ตลาดแรงงานจะถูกแทนที่ด้วยคอมพิวเตอร์ หุ่นยนต์ และปัญญาประดิษฐ์ โดยที่เห็นตอนนี้ เราก็เริ่มเห็นว่างานบางสายเริ่มถูกแทนที่ด้วยเครื่องไปเยอะแล้ว เช่น หุ่นยนต์ที่รับรายการสั่งซื้อออนไลน์และนำของจัดส่งให้ผู้ซื้อโดยอัตโนมัติ หรือสายด่วนบริการลูกค้าที่สามารถรับฟังปัญหาและตอบคำถามตามที่ลูกค้าต้องการได้โดยใช้ปัญญาประดิษฐ์ที่สามารถใช้ภาษาได้ใกล้เคียงกับมนุษย์ในด้านนี้ นอกจากนั้นแล้วเทคโนโลยีใหม่ๆ ที่นักวิจัยและพัฒนาในปัจจุบันกำลังลงมือลงแรงสร้างกันต่างก็ชี้ให้เห็นถึงอนาคตข้างหน้าที่ปัญญาประดิษฐ์จะเข้ามามีบทบาทมากขึ้น เช่น เทคโนโลยีพาหนะที่ขับเคลื่อนด้วยตัวเอง (Autonomous Vehicles) อาจจะนำมาใช้เพื่อแทนที่คนขับรถที่เป็นมนุษย์ได้ทั้งหมด เมื่อเทคโนโลยีมีความปลอดภัยกว่านี้ อีกตัวอย่างหนึ่งคือเทคโนโลยีทางภาษาที่ใช้สร้างผู้ช่วยอัจฉริยะอย่าง Google Assistant ที่สามารถพูดจาโต้ตอบรับคำสั่งเราและพูดจาโต้ตอบกับบุคคลอื่นๆ เฉกเช่นเลขานุการส่วนตัว หรือแปลเอกสารให้ได้อัตโนมัติโดยไม่ต้องจ้างนักแปลมืออาชีพ

เทรนด์นี้จะเดินหน้าต่อไปถึงสังคมอนาคตที่ปัญญาประดิษฐ์ทำหน้าที่แทนมนุษย์ทุกสิ่งหรือไม่ หรือว่าจะเดินหน้าต่อไปจนถึงระดับที่ปัญญาประดิษฐ์ฉลาดจนกระทั่งสามารถพัฒนาตัวมันเองได้โดยไม่ต้องอาศัยมนุษย์และยึดครองโลกได้ในที่สุด อีลอน มัสก์ (Elon Musk) ผู้ก่อตั้งบริษัทเทคโนโลยีล้ำอนาคตอย่าง SpaceX หรือ Tesla เข้ามาลงทุนในบริษัทที่ทำเรื่องปัญญาประดิษฐ์อย่างจริงจัง เนื่องจากมีความเชื่อที่ว่าปัญญาประดิษฐ์นั้นจำเป็นต้องถูกควบคุมจากทุกฝ่ายเพื่อไม่ให้เกิดเหตุร้าย เช่น เทคโนโลยีทางข้อมูลขนาดใหญ่อาจถูกนำไปใช้ในการก่อการร้าย หรือหุ่นยนต์ปัญญาประดิษฐ์อาจประกาศสงครามต่อมนุษยชาติ ความเชื่อเหล่านี้เป็นความเชื่อที่เกินจริงหรือไม่ และเรามาถึงจุดนี้ได้อย่างไร ที่เราจะต้องพูดถึงความอยู่รอดของมนุษยชาติและภัยคุกคามของปัญญาประดิษฐ์ซึ่งนักวิพากษ์เริ่มคาดคะเนว่าจะคืบคลานเข้ามาทุกขณะ แล้วเราจะมีทางรับมือกับสังคมที่จะถูกเปลี่ยนแปลงไปด้วยเทคโนโลยีปัญญาประดิษฐ์อย่างไร

ภาพจำลองของโครงข่ายประสาทเทียม (Artificial Neural Network)
Deep Learning ปฏิวัติด้านปัญญาประดิษฐ์
เทคโนโลยีทางด้าน Deep Learning ขับเคลื่อนความก้าวล้ำของ AI ในช่วง 10 ปีที่ผ่านมา ที่จริงแล้วเทคโนโลยี Deep Learning ไม่ใช่เทคโนโลยีที่ใหม่เลย แต่เป็นเทคโนโลยีเดียวกันกับที่เมื่อก่อนเรียกกันว่า Neural Network นักวิจัยสมัยนี้ก็ยังใช้อยู่ทั้งสองชื่อสลับสับกันได้ Deep Learning หรือ Neural Network เมื่อ 20 ปีที่แล้วมานั้น เป็นเพียงโมเดลทางคณิตศาสตร์ที่ทฤษฎีอ้างไว้ว่า สามารถเรียนรู้ความเกี่ยวโยงของ Input และ Output ในลักษณะใดก็ได้ หากให้ข้อมูลกับเครื่องมากพอ แต่เป็นทฤษฎีที่ไม่สามารถพิสูจน์ได้ในทางปฏิบัติจริง เนื่องจากไม่มีคอมพิวเตอร์ที่มีสมรรถภาพสูงเหมือนสมัยนี้ รวมทั้งนักวิจัยยังไม่มีทักษะความเชี่ยวชาญในการปรับจูนโมเดลให้เรียนรู้ได้เร็วพอเมื่อต้องให้เครื่องเรียนรู้จากข้อมูลขนาดมหึมา Deep Learning กลับมาได้รับความนิยมอีกครั้งจากนักวิจัยทางด้านวิทยาศาสตร์คอมพิวเตอร์เนื่องด้วยอย่างน้อยสองปัจจัย ปัจจัยที่หนึ่งคือปัจจุบันนี้เครื่องคอมพิวเตอร์นั้นมีความสามารถในการคำนวณได้เร็วขึ้นและมีราคาถูกลง ทำให้การวิจัยพัฒนา และการลองผิดลองถูกนั้นเป็นไปได้อย่างรวดเร็วขึ้น ปัจจัยที่สองคืออินเตอร์เน็ตช่วยอำนวยให้การสร้างคลังข้อมูลเป็นไปได้อย่างราบรื่นและรวดเร็ว เราสามารถใช้ประโยชน์จากคนหมู่มากบนอินเตอร์เน็ต (Crowdsource) ในการสร้างคลังข้อมูลขนาดใหญ่ซึ่งเป็นส่วนสำคัญมากเนื่องจาก Deep Learning จำเป็นต้องเรียนรู้ความเกี่ยวโยงของ Input และ Output จากข้อมูลที่มนุษย์ผลิตขึ้นโดยตรง
ช่วงประมาณปี 2012 นักวิจัยได้นำเทคโนโลยี Deep Learning มาประยุกต์ใช้ได้สำเร็จ โดยสอนให้เครื่องคอมพิวเตอร์ดักจับวัตถุชนิดต่างๆ จากรูปภาพโดยอัตโนมัติโดยข้อมูลที่ใช้ในการฝึกเครื่องคอมพิวเตอร์นั้นมาจากการ Crowdsourcing และมีขนาดใหญ่มาก เทคโนโลยีและการฝึกเครื่องคอมพิวเตอร์ในลักษณะเดียวกันนี้ยังสามารถสอนให้เครื่องถอดเสียงพูดของมนุษย์ให้เป็นตัวอักษรได้โดยอัตโนมัติด้วยความแม่นยำสูงมาก ซึ่งถ้าเปรียบตัวเลขความแม่นยำของเทคโนโลยี Deep Learning กับตัวเลขความแม่นยำของวิธีที่ผ่านมา เรียกได้ว่าไม่ติดฝุ่นเลยทีเดียว และนับเป็นเทคโนโลยีที่ปฏิวัติวงการของ AI

หลักการการทำงานของ Deep Learning คือการแปลง Input ที่มีลักษณะเป็นตัวเลข ให้เป็น Output ที่เราต้องการโดยอาศัยข้อมูลจำนวนมาก เช่น ถ้า Input คือเสียงของภาษา Output คือตัวหนังสือที่ต้องการจะถอดจากเสียงภาษานั้นๆ เราจะต้องอาศัยข้อมูล Input เสียงพูดของคนจริงๆ ที่เราไปอัดเก็บ และ Output คือบทถอดเสียงคนพูดที่เรานำมาพิมพ์เองเป็นตัวอักษร ขั้นตอนการทำงานขั้นแรกของ Deep Learning คือการเปลี่ยนข้อมูลที่เราต้องการจะประมวลให้เป็นตัวเลข 100 ตัวหรือ 200 ตัว หรือ 8,000 ตัวตามแต่จุดประสงค์ที่เราจะต้องการนำไปใช้และตามความเหมาะสมกับลักษณะของข้อมูลดิบ หลังจากนั้นแล้วตัวเลขเหล่านี้จะถูกแปลงไปเป็นค่าอื่นๆ ด้วย วิธีบวกลบคูณหารกับค่าต่างๆ โดยเฉพาะอย่างยิ่งการคูณเมทริกซ์และการใช้ฟังก์ชันที่ไม่ใช่เชิงเส้น โดยการแปลงค่านี้จะเป็นการแปลงค่าเพื่อที่จะไปเปลี่ยนไปเป็นค่า Output ที่อยากได้ แล้วกระบวนการแปลงค่านี้เครื่องจะรู้ได้อย่างไรว่าจะต้องทำในลักษณะไหนจะคูณ 1.2 หรือคูณ 0.4 ดี หรือนำไปคูณกับเมทริกซ์ไหน เครื่องจะเรียนรู้กระบวนการแปลงค่าต่างๆ นี้ผ่านทางข้อมูลที่เราป้อนให้กับเครื่อง ซึ่งข้อมูลนี้จะต้องมีค่า Input ที่เราสนใจและค่า Output ที่ถูกต้อง วิธีการแปลงค่า Input ให้เป็น Output นั้นเราจะเก็บไว้อยู่ในโมเดล กระบวนการนี้ศัพท์เทคนิคจะเรียกว่าการ ”ฝึกฝนโมเดล” (Model Training) สรุปได้ว่าการจัดสร้างระบบปัญญาประดิษฐ์ในยุคปัจจุบันนี้ส่วนใหญ่จำเป็นต้องระบุว่า Input คืออะไร Output คืออะไร โครงสร้างของโมเดลเป็นอย่างไร และที่สำคัญคือจะต้องหาข้อมูลจำนวนมากในการฝึกฝนโมเดลที่เราตั้งไว้
ตามทฤษฎีของปัญญาประดิษฐ์แล้วมีปัญญาประดิษฐ์อยู่ 2 แบบด้วยกันคือปัญญาประดิษฐ์แบบอ่อน (Weak AI) กับปัญญาประดิษฐ์แบบเข้ม (Strong AI) ปัญญาประดิษฐ์ทั้ง 2 แบบนี้ต่างกันด้วยคุณลักษณะที่ว่า ปัญญาประดิษฐ์แบบเข้มนั้นมีปัญญาและความฉลาดโดยทั่วไปที่สามารถนำไปประยุกต์ใช้ทำหน้าที่ต่างๆ ได้มาก ตัวอย่างเช่น เครื่องที่เข้าใจภาษามนุษย์ด้วยปัญญาประดิษฐ์แบบเข้มนั้นจะต้องสามารถทำหน้าที่ทางภาษาได้ในทุกรูปแบบ ไม่ว่าจะเป็นการอ่านทำความเข้าใจ การคุยสนทนาเพื่อบรรลุวัตถุประสงค์ในการสื่อสารต่างๆ การสรุปความ การแปลความจากภาษาหนึ่งไปอีกภาษาหนึ่ง หรือว่าการใช้เหตุผล และการตอบคำถามต่างๆ โมเดลปัญญาประดิษฐ์ที่ใช้ Deep Learning ในปัจจุบันนี้ ล้วนแต่เป็นปัญญาประดิษฐ์แบบอ่อนเพราะว่าเป็นโมเดลที่สร้างขึ้นมาเพื่อทำการใดการหนึ่ง เวลาฝึกโมเดลนั้นส่วนใหญ่แล้วจะฝึกด้วยชุดข้อมูลที่เฉพาะเจาะจงกับหน้าที่ที่จะต้องทำ และไม่สามารถต่อขยายไปกับหน้าที่อื่นๆ AI ที่ใช้อยู่ในระบบผู้ช่วยอัจฉริยะ เช่น Alexa ของบริษัท Amazon และ Siri ของบริษัท Apple ล้วนเป็นปัญญาประดิษฐ์แบบอ่อน ระบบเหล่านี้ถูกสร้างมาเพื่อทำอยู่ไม่กี่สิ่งอย่างที่นักเขียนโปรแกรมนั้นจะต้องตั้งไว้ก่อน เพราะฉะนั้นเครื่องนั้นไม่ได้มีความสามารถในการทำความเข้าใจทุกสิ่งทุกอย่างที่ผู้ใช้ระบบต้องการ บุคคลทั่วไปที่บริโภคข่าวด้านสังคมและเทคโนโลยีที่นำเสนอเกี่ยวกับ AI มักจะได้รับรู้ถึง AI ในแง่ที่ว่ามันสามารถทำแทนมนุษย์ได้ทุกอย่างจริงๆ ซึ่งหมายความถึงปัญญาประดิษฐ์แบบเข้ม แต่ที่จริงแล้ว ถ้าลองคิดกลับไปให้ลึกๆ จะพบว่า AI ทุกตัวที่เราใช้อยู่ในชีวิตประจำวันนี้ เป็นปัญญาประดิษฐ์แบบอ่อนที่ไม่สามารถนำไปประยุกต์ใช้กับ Application อื่นๆ ได้โดยตรงโดยไม่ต้องพัฒนาและฝึกโมเดลขึ้นมาใหม่ตั้งแต่ต้นจนจบ ในฐานะสมาชิกของประชาคมดิจิตัลที่คลุกคลีกับเทคโนโลยีอยู่ทุกครู่ชั่ววัน เราควรพินิจรายละเอียดและประเมินผลกระทบของงานวิจัยและพัฒนาที่กำลังเกิดขึ้นในขณะนี้ว่าจะนำไปสู่ปัญญาประดิษฐ์แบบเข้มและส่งผลกระทบต่อสังคมอย่างที่นักคิดหลายคนได้คาดการณ์เอาไว้หรือไม่
เครื่องคอมพิวเตอร์เข้าใจภาษามนุษย์ได้อย่างไร
ภาษาเป็นสิ่งที่สะท้อนให้เห็นถึงปัญญาของมนุษย์ มนุษย์สื่อสารกันด้วยการเขียนสัญลักษณ์ต่างๆ ที่ประกบประกอบขึ้นตามระเบียบแบบแผน หรือใช้ปาก ลิ้น และหลอดลมในการสร้างเสียงต่างๆ ที่ทำให้ส่งข้อความไปสู่ผู้ฟังได้ โดยไม่จำกัดว่าสารนั้นมีความซับซ้อนขนาดใด นักภาษาศาสตร์หลายคณะพบหลักฐานว่า สัตว์บางชนิดนั้นสามารถสื่อสารด้วยภาษา แต่ยังไม่มีหลักฐานใดที่พบว่าสารที่สัตว์เหล่านี้สื่อมีความซับซ้อนเท่าสารของมนุษย์
ภาษานอกจากเป็นเครื่องมือในการสื่อสารแล้ว ยังเป็นสิ่งที่แสดงถึงปัญญาในฐานะสิ่งที่รวบรวมความคิด และการใช้เหตุผลของมนุษย์ เช่น การตอบคำถามนั้นผู้ตอบจะต้องเข้าใจคำถามว่าเป็นคำถามชนิดใด และความหมายของแต่ละคำที่ใช้ในบริบทนั้นๆ มีความหมายว่าอย่างไร เช่น “นายกรัฐมนตรีเปิดโครงการใหม่ที่จังหวัดนครราชสีมาเวลากี่โมง” ผู้ฟังจะต้องทราบว่า นายกรัฐมนตรีนั้นหมายถึงนายกรัฐมนตรีคนปัจจุบันไม่ใช่คนก่อนๆ ถึงแม้ว่าประโยคนั้นไม่ได้บอกไว้โดยตรงก็ตาม คำว่าเปิดนั้นหมายถึงเริ่มต้นไม่ได้หมายถึงเปิดกล่องหรือเปิดตู้ จังหวัดนครราชสีมานั้นหมายถึงที่ที่หนึ่งที่มีอยู่จริงในโลกนี้ กล่าวคือต้องเข้าใจความหมายของประโยคนี้ลงลึกไปกว่าระดับคำ ต้องเข้าใจความหมายของคำที่ต่างออกไปในแต่ละบริบท รวมถึงความรู้เกี่ยวกับโลก เมื่อผู้ฟังต้องการจะตอบคำถามนี้ นอกจากจะต้องให้คำตอบที่ถูกต้องแล้ว คำตอบที่ต้องเปล่งออกมาหรือเขียนออกมานั้นจะต้องถูกต้องตามไวยากรณ์เพื่อที่จะทำให้สื่อสารได้รวดเร็วและมีประสิทธิภาพมากขึ้น เพราะเป็นแบบแผนที่สังคมตกลงกันไว้แล้วว่า ประธานควรจะขึ้นก่อนหรือว่ากริยาควรจะขึ้นก่อน หรือกริยาจะต้องเปลี่ยนรูปตามประธานหรือไม่ ปัญญาประดิษฐ์ทางด้านภาษานั้นจึงเป็นสิ่งที่น่าจับตามอง เนื่องจากเป็นปัญญาที่มีความเป็นมนุษย์อยู่มากที่สุด
เทคโนโลยีทางด้านภาษาถูกเรียกกันในวงการว่าการประมวลภาษาธรรมชาติ (Natural Language Processing) และเป็นแขนงหนึ่งของศาสตร์ด้านปัญญาประดิษฐ์ ทั้งยังเป็นแขนงหนึ่งที่เทคโนโลยี Deep Learning เข้ามามีบทบาทอย่างมากในช่วงทศวรรษที่ผ่านมา นักวิทยาศาสตร์คอมพิวเตอร์และนักภาษาศาสตร์ได้ร่วมมือกันพัฒนาและวิจัยเทคโนโลยีการประมวลภาษาธรรมชาติเพื่อให้คอมพิวเตอร์นั้นสามารถทำหน้าที่ต่างๆ ทางภาษาแทนมนุษย์ได้ นักภาษาศาสตร์จะทำหน้าที่เป็นผู้ตั้งทฤษฎีเกี่ยวกับกลไกการทำงานของภาษาทั้งด้านโครงสร้างไวยากรณ์และด้านความหมาย ส่วนนักวิชาการคอมพิวเตอร์นั้นเป็นผู้นำทฤษฎีไปทดสอบเพื่อประยุกต์ใช้กับเทคโนโลยีที่ต้องการ ว่ากันว่าความสำเร็จสูงสุดของการประมวลภาษาธรรมชาตินั้น คือการสร้างหุ่นยนต์นักสนทนา (Chatbot หรือ Conversational Agent) ที่สามารถโต้ตอบกับมนุษย์ได้โดยที่เราเองไม่สามารถแยกออกเลยว่าเรากำลังคุยกับคนหรือหุ่นยนต์อยู่ นอกจากนั้นแล้วหุ่นยนต์นักสนทนานี้จะต้องสามารถหาความรู้ต่างๆ จากอินเทอร์เน็ตและทำความเข้าใจเพื่อที่จะนำความรู้มาตอบคำถามต่างๆ ที่มนุษย์ถามได้อย่างถูกต้อง หุ่นยนต์นักสนทนานั้นมีส่วนประกอบใหญ่ๆ อยู่ 2 ส่วนคือ หน่วยการถอดเสียงพูดเป็นตัวอักษร และหน่วยการทําความเข้าใจภาษา
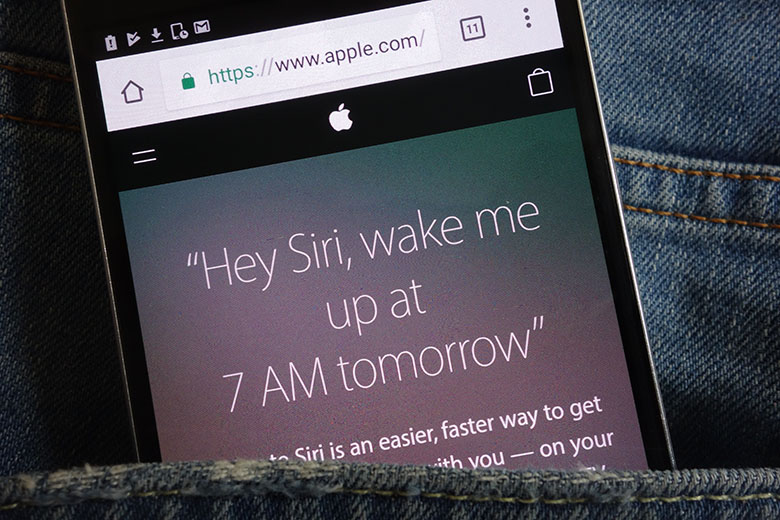
ความก้าวหน้าของเทคโนโลยีด้านการถอดเสียงพูดเป็นตัวอักษร (Speech Recognition) ได้ผลเก่งเทียบเท่าหรือเกินคนไปแล้วในบางกรณี เครื่องถอดความนั้นผิดพลาดเพียง 4-5 เปอร์เซ็นต์เท่านั้น และแน่นอนว่า Speech Recognition นี้ใช้โมเดล Deep Learning เป็นแกนหลักในการแปลงเสียงให้เป็นคำ แต่ว่าผลการศึกษาค้นคว้าเหล่านี้มาจากการทดสอบกับข้อมูลภาษาที่เป็นภาษาอังกฤษจากฝั่งอเมริกาเท่านั้น ไม่มีสิ่งที่รับประกันว่า ถ้าเราใช้วิธีเดียวกันนี้กับภาษาอื่นๆ แล้วจะได้คุณภาพของการถอดความจากเสียงในระดับเดียวกัน ข้อจำกัดของเทคโนโลยีนั้นยังมีอยู่มาก ภาษาอังกฤษเป็นภาษาที่เป็นสากล มีผู้พูดภาษาอังกฤษเป็นภาษาต่างประเทศเป็นพันล้านคน และยังไม่มีผลการศึกษาออกมาว่า ถ้าพูดสำเนียงอื่นติดปนเข้ามานั้น คุณภาพของการถอดความจะลดลงไปเท่าไร ถ้าผู้อ่านอยากลองพิสูจน์ด้วยตัวเอง ให้ลองหยิบโทรศัพท์ขึ้นมา แล้วลองใช้ฟังก์ชัน เสียงเป็นอักษร (Speech to Text) แล้วพูดด้วยสำเนียงไทยๆ หรือพูดแล้วมีผิดไวยากรณ์ไปบ้าง แล้วสังเกตผลจะออกมาเป็นอย่างไร สิ่งนี้เป็นสิ่งที่สะท้อนให้รู้ว่า เทคโนโลยีที่ข่าวและนักวิทยาศาสตร์เองนำเสนอนั้นเมื่อดูผิวเผินอาจจะสวยหรูขนาดที่ทำให้เราเชื่อไปว่า AI นั้นมาถึงจุดสูงสุดแล้ว เครื่องสามารถฟังสิ่งที่เราพูดแล้วเข้าใจได้เหมือนกันกับคนเจ้าของภาษา ข้อด้อยในประเด็นนี้ไม่ได้มีนัยยะสำคัญต่อการวิจัยเท่านั้น แต่ยังมีผลต่อการพัฒนาผลิตภัณฑ์ต่างๆ ด้วย เช่น ถ้า Siri ทำงานได้ไม่สมบูรณ์ถ้าผู้ใช้ไม่พูดภาษาอังกฤษเป็นภาษาแม่ กลุ่มลูกค้าจำนวนไม่น้อยก็จะไม่รู้สึกปลื้มกับผลิตภัณฑ์เท่ากับผู้ใช้ชาวอเมริกันที่พูดโดยไม่มีสำเนียง ข้อสังเกตที่สำคัญอีกประการหนึ่งคือ โมเดลต้องใช้ข้อมูลในการฝึกฝนจำนวนมหาศาล ตัวอย่างเช่น ระบบ Speech Recognition ของบริษัท Google นั้น ต้องใช้ข้อมูลเสียงจากมนุษย์เป็นจำนวน 12,500 ชั่วโมง และจะต้องใช้คนจริงๆ ถอดความเป็นตัวอักษรทั้งหมดทั้ง 12,500 ชั่วโมง เพื่อจะนำไปฝึกโมเดลให้กับ Speech Recognizer ข้อมูลเหล่านี้เก็บมาจากผู้ใช้ผลิตภัณฑ์ของ Google จริงๆ แต่สำหรับบางภาษาแล้ว แทบจะเป็นไปไม่ได้เลยที่จะเก็บข้อมูลได้มากพอที่จะทำเป็นผลิตภัณฑ์ขึ้นมา ปัญหาข้อมูลไม่เพียงในลักษณะนี้เรียกว่า Cold Start Problem ไม่มีผลิตภัณฑ์ไม่มีข้อมูล ไม่มีข้อมูลไม่มีผลิตภัณฑ์ นอกจากนั้นแล้วบางภาษาอาจจะไม่มีเจ้าของภาษามากพอที่จะรวบรวมข้อมูลได้เพียงพอที่จะฝึกโมเดล Deep Learning ให้ได้ความสามารถระดับที่เราต้องการ
ส่วนประกอบอีกส่วนหนึ่งของหุ่นยนต์นักสนทนาคือหน่วยวิเคราะห์ความหมาย เครื่องต้องสกัดความหมายออกมาจากคำที่ได้ยินมา ปัจจุบันยังคงเป็นเรื่องถกเถียงกันอย่างมากว่าความเข้าใจของภาษาคืออะไร และสามารถบวกเข้าสู่การถกเถียงทางปรัชญาได้อย่างมากมายว่าอะไรคือความหมายของคำ รู้ได้อย่างไรว่าเราเข้าใจคำคำหนึ่งอย่างแท้จริง ผลคือเราไม่มีกฏเกณฑ์แน่นอนว่าความหมายของคำแต่คำนั้นมันมีที่มาที่ไปอย่างไร เราจะสอนให้เครื่องเข้าใจภาษาอย่างที่คนเข้าใจได้อย่างไร แล้วถ้าพิจารณาโมเดลที่เราใช้ในในปัจจุบันนี้ เรามีศักยภาพเพียงใดในการพัฒนาไปสู่โมเดลความเข้าใจภาษาธรรมชาติโดยทั่วไปกล่าวคือไม่ได้ทำมาเพื่อจุดประสงค์ใดจุดประสงค์หนึ่งโดยเฉพาะ โมเดลที่เราสร้างไว้เพื่อ Application พวกผู้ช่วยอัจฉริยะต่างๆ นั้นจะต้องใช้ความเข้าใจภาษาใน 3 ระดับ คือ
ความเข้าใจความหมายระดับบทสนทนา เครื่องจะต้องจำว่าถามอะไรไปบ้างแล้ว และกำลังพูดเรื่องอะไรอยู่ นอกจากจะต้องแปลเสียงเป็นคำได้อย่างถูกต้องแล้วเราจะต้องเข้าใจบริบทของบทสนทนาด้วยเช่นว่าก่อนหน้านี้ผู้ใช้ซอฟต์แวร์ถามคำถามมาหรือเปล่าหรือพูดจาทักทายเฉยๆ แล้วเครื่องนี้ก็ต้องจำให้ได้ด้วยว่าถามคำถามอะไรไปแล้วบ้าง และบทสนทนานี้กำลังมุ่งหน้าไปทางไหน ผู้สนทนามีจุดประสงค์อะไรเป็นจุดประสงค์หลัก เช่น ต้องการคุยเพลินๆ ต้องการให้เครื่องช่วยจองโรงแรม หรือต้องการให้เครื่องปรับอุณหภูมิห้อง
ความเข้าใจความหมายระดับประโยค กล่าวคือการเข้าใจเจตนาของผู้พูดอย่างที่กล่าว แปลว่าโมเดลที่เรากำลังใช้อยู่ในปัจจุบันนี้จะถูกจะทำขึ้นมาเพื่อจุดประสงค์ใดจุดประสงค์หนึ่งโดยเฉพาะ เพราะฉะนั้นเมื่อผู้พูดพูดสิ่งใดสิ่งหนึ่งมา เครื่องก็ต้องเข้าใจว่าผู้พูดนั้นมีจุดประสงค์อะไร เช่น ถามคำถามบอกให้ไปทำสิ่งใดสิ่งหนึ่ง หรือทักทาย หรือตอบคำถามที่เครื่องเคยถามไป หรือต้องการให้ขยายความ หรือต้องการให้พูดอีกครั้งหนึ่ง และอื่นๆ ซึ่งในทางภาษาศาสตร์แล้วเป็นสิ่งที่ยากเช่นกัน เช่นการสั่งให้เครื่องไปทำสิ่งใดสิ่งหนึ่งแทนเรา แล้วไม่จำเป็นต้องพูดออกคำสั่งเสมอไป แต่อาจจะพูดอ้อมๆ เช่น “ช่วยตั้งเวลาปลุกอีก 10 นาทีได้ไหมครับ” ประโยคนี้โดยทางโครงสร้างแล้วไม่ได้เป็นประโยคคำสั่ง แต่ว่าเป็นประโยคคำถาม อย่างไรก็ตามเมื่อนำไปใช้ในบทสนทนาจริงๆ แล้ว จะเป็นประโยคคำถามที่มีเจตนาในการออกคำสั่ง ซึ่งจุดนี้เองจะต้องนำทฤษฎีทางภาษาศาสตร์มาเป็นกรอบความคิดว่าในการออกคำสั่งนั้นสามารถทำได้ในลักษณะใดบ้าง
ระดับล่างสุด คือความรู้ความเข้าใจระดับคำศัพท์เช่นถ้าผู้ใช้บอกให้ตั้งเวลา 10 นาที ควรจะรู้ว่า 10 นาทีนี้ไม่ใช่ 10 โมงแต่เป็นระยะเวลาที่ต้องการตั้งปลุกเพราะว่า 10 มีความหมายต่างกันใน 2 ประโยคนี้ หรือยกตัวอย่างที่ซับซ้อนขึ้นมาอีกระดับหนึ่ง เช่น ผู้ใช้อาจจะพูดว่า “เปิดเพลงอะไรก็ได้ของ Imagine Dragons” ประโยคนี้พูดถึงวง Imagine Dragons ซึ่งเป็นวงดนตรีวงหนึ่งในโลกนี้ไม่ใช่ชื่อละคร หรือชื่อเมือง เพราะฉะนั้นเครื่องก็ต้องรับรู้และเข้าใจด้วยว่ากำลังพูดถึงชื่อวงที่อยู่ในโลกจริงๆ ซึ่งในตอนนี้โมเดลส่วนใหญ่สามารถจัดการได้อย่างเหมาะสมแล้ว โดยอิงฐานความรู้จาก Wikipedia ซึ่งมีความรู้ค่อนข้างครบถ้วน และเราเรียกระบบนี้ว่า Named-entity Recognition หรือการรู้จำตัวตนที่มีชื่อ ซึ่งหมายความถึงชื่อคน ชื่อวงดนตรี ชื่อสถานที่ ชื่อประเทศ ชื่อองค์กร ชื่อเหล่านี้ไม่ใช่ชื่อลอยๆ แต่เป็นชื่อที่พูดถึงตัวตนที่มีอยู่จริงในโลก ระบบนี้เป็นส่วนประกอบที่มีความสำคัญมาก นอกจากจากจะต้องรู้จำชื่อของตัวตนต่างๆ ที่รู้จักกันโดยกว้างแล้ว โมเดลก็จะต้องดูด้วยว่าถ้าผู้ใช้บอกว่า “ช่วยต่อสายคุณแม่หน่อย” คุณแม่ในประโยคนี้ ผู้ใช้พูดถึงคุณแม่ของผู้ใช้เอง ถึงแม้ว่าในประโยคไม่ได้บอกตรงๆ ว่าคุณแม่ของใคร คุณแม่คนไหน ซึ่งความเข้าใจตรงนี้แสดงถึงความเข้าใจของคำศัพท์ว่าศัพท์คำนี้ไม่ได้หมายถึงคอนเซ็ปต์โดยรวม แต่หมายถึงคน ตัวตน หรือองค์กรที่มีอยู่จริงในโลก
ความรู้ระดับคำศัพท์นั้นเป็นสิ่งที่นักภาษาศาสตร์ศึกษากันมาอย่างกว้างขวางและมีโมเดลทางความหมายระดับคำหลากหลายแบบ เทคโนโลยีด้าน Deep Learning นั้นก็ถูกนำมาช่วยในการสอนให้เครื่องเข้าใจความหมายของคำได้ดีในระดับหนึ่ง แต่ยังคงห่างไกลจากระดับความสามารถของมนุษย์เจ้าของภาษา ปัจจุบันความเข้าใจระดับบทสนทนานั้นถึงระดับที่สามารถนำมาใช้ในเชิงพาณิชย์ได้จริงแล้ว ชาวเน็ตผู้ติดตามเทคโนโลยีก็ทึ่งไปตามๆ กัน ตอนที่บริษัท Google เปิดตัว Google Assistant ที่สามารถต่อโทรศัพท์พูดคุยสนทนากับร้านอาหารและจองโต๊ะได้อย่างคล่องแคล่วเหมือนกับมนุษย์ เป็นหลักฐานให้เห็นถึงความก้าวหน้าของความเข้าใจบทสนทนาของเครื่อง แต่ว่าวาทกรรมหรือบทสนทนาในบริบทของการจองโต๊ะอาหารนั้นมีวงจำกัด เพราะต่างคนต่างรู้เจตนาของบทสนทนาตั้งแต่ต้นแล้ว แต่ในบทสนทนาทั่วไป ผู้พูดอาจจะไม่รู้ถึงจุดมุ่งหมายหลักของบทสนทนา ทำให้ความรู้เข้าใจโดยรวมของบทสนทนาขาดความสอดคล้องกัน เทคโนโลยีความเข้าใจระดับประโยคและระดับบทสนทนานั้นยังคงพร่องความรู้ทางทฤษฎี และทางโมเดล Deep Learning ที่สามารถนำมาประยุกต์ใช้ให้เครื่องเข้าใจภาษาในระดับนี้ได้ ทำให้ไม่สามารถนำไปประยุกต์ใช้ได้กว้างขวางกว่าที่เป็นอยู่ในปัจจุบันนี้ และยังห่างไกลจากระดับปัญญาประดิษฐ์แบบเข้มที่สามารถเข้าใจประโยคและบทสนทนาในทุกบริบททุกรูปแบบได้
ปัญญาประดิษฐ์ที่รู้และเข้าใจทุกสิ่งทุกอย่างในโลก
อีกด้านหนึ่งที่ผู้วิจัยจากหลายที่ทั่วโลกกำลังประชันกับปัญญาประดิษฐ์ที่ตนประดิษฐ์ขึ้นเอง คือเวทีการสร้างระบบการตอบคำถามโดยอัตโนมัติ ซึ่งผู้ใช้จะถามคำถามอะไรก็ได้ที่มีคำตอบแน่นอน เช่น ใครคือนายกฯ คนปัจจุบันของประเทศแคนาดา และถามได้โดยไม่ต้องจํากัดหัวข้อ ขอให้เป็นคำถามที่มีคำตอบก็เพียงพอแล้ว แล้วเครื่องก็พยายามจะสรรหาคำตอบและตอบมาให้เป็นภาษาคน งานวิจัยทางด้านนี้ ยังไม่สามารถขยายให้ตอบคำถามโดยไม่มีการจำกัดหัวข้อและไม่บอกก่อนว่าความรู้ที่จะนำมาตอบจะต้องดึงมาจากแหล่งไหน งานวิจัยในช่วง 3-4 ปีที่ผ่านมานี้ทดสอบการตอบคำถาม โดยการทดสอบระบบการอ่านทำความเข้าใจ (Reading Comprehension) กล่าวคือเครื่องได้ข้อมูลมาเป็นคำถาม พร้อมกับย่อหน้า 1 ย่อหน้าและจะต้องตอบคำถามให้ถูกโดยใช้ข้อมูลจากย่อหน้าที่ได้รับมา หรือบอกให้ได้ว่าย่อหน้าที่ได้มานั้นมีข้อมูลไม่เพียงพอ ถึงแม้ว่าปัญหาหลักของการตอบปัญหาทุกหัวข้อนั้นถูกย่อยลงมาให้เหลือจำกัดเพียงหัวข้อที่ย่อหน้านั้นกำหนด แต่ว่าระบบที่ดีที่สุดเท่าที่มีมาในตอนนี้นั้นยังไม่มีความสามารถเทียบเท่ากับความสามารถของมนุษย์ได้ ความสามารถของมนุษย์ของการทดสอบชุดนี้อยู่ที่ประมาณ 88 เปอร์เซ็นต์แต่ว่าระบบที่ดีที่สุดเท่าที่เราเคยเห็นมานั้นสามารถทำได้เพียง 75 เปอร์เซ็นต์เท่านั้น แต่ถ้านำไปทดสอบโดยไม่แนะว่าคำตอบจะต้องมาจากภายในย่อหน้าที่กำหนดให้ ความสามารถของเครื่องนั้นก็คงมีตัวเลขต่ำลงไปอีก
นอกจากนั้นแล้ว ระบบคำถามอนุมัติในระดับที่เรามีอยู่ในตอนนี้นั้นจำกัดอยู่ที่คำถามที่เป็นเกร็ดความรู้ เช่น แม่น้ำสายใดยาวที่สุด สงครามโลกครั้งที่ 2 เกิดขึ้นเมื่อปีใด เป็นต้น แต่ยังไม่มีความสามารถในการตอบคำถามที่เป็นปลายเปิด เช่นทำไมท้องฟ้าถึงเป็นสีฟ้า หรือภาวะโลกร้อนนั้นเป็นเรื่องจริงหรือเป็นเรื่องเท็จ เพราะอะไร เป็นต้น ข้อจำกัดของปัญญาประดิษฐ์ที่ใช้ตอบคำถามอัตโนมัติที่เราได้ยกตัวอย่างขึ้นมานั้น สะท้อนให้เห็นถึงว่าความก้าวหน้าของปัญญาประดิษฐ์ในเชิงของภาษาและในเชิงความรู้ ว่ายังด้อยกว่าระดับที่เทียบเท่ากับมนุษย์เป็นอย่างมาก หากเรามีปัญญาประดิษฐ์ที่เก่งจริง เราก็ควรจะมีระบบที่สามารถตอบคำถามใดก็ได้ ในหัวข้อใดก็ได้ และในลักษณะใดก็ได้ เพราะว่าเครื่องนั้นมีความสามารถเปิดหาความรู้จากอินเทอร์เน็ตโดยอัตโนมัติ และดึงมาตอบคำถามได้อย่างถูกต้อง แต่ในปัจจุบันนี้ เทคโนโลยีนั้นยังห่างไกลจากในระดับนั้นมาก และความก้าวหน้าของงานวิจัยก็ไม่ได้เป็นไปอย่างก้าวกระโดด แต่เป็นไปอย่างค่อยเป็นค่อยไปและยังไม่เห็นแนวโน้มว่าจะมีการปฏิวัติครั้งใหม่อีกครั้งหนึ่งทางด้านเทคโนโลยีเร็วๆ นี้ ที่สามารถทำให้เรากระโดดจากระดับที่เป็นอยู่นี้ ถึงระดับที่เทียบเท่ากับมนุษย์อย่างแท้จริงได้ในเวลาอันใกล้
AI จะมาครองโลกเร็วๆ นี้หรือเปล่า
ตอบสั้นๆ คือ ไม่ เมื่อดูจากความก้าวหน้าทางการวิจัยเกี่ยวกับเทคโนโลยีทางภาษาและปัญญาประดิษฐ์เกี่ยวกับภาษาตามที่ยกตัวอย่างและอธิบายขึ้นมาข้างต้นแล้ว การพัฒนาปัญญาประดิษฐ์ในปัจจุบันนี้เป็นการพัฒนาเฉพาะชิ้น ไม่ได้เน้นการพัฒนาปัญญาประดิษฐ์ที่มีความสามารถในการใช้ภาษาหรือแก้ปัญหาโดยทั่วไป เมื่อตัดสินจากอัตราความก้าวหน้าทางด้านเทคโนโลยีของปัญญาประดิษฐ์ในขณะนี้ พอจะบอกได้ว่า เทคโนโลยีปัญญาประดิษฐ์นั้นยังไม่สามารถมาแทนที่มนุษย์ได้ทั้งหมดในเวลาอันใกล้ แต่ว่าจะนำมาช่วยย่นเวลาในการทำงานต่างๆ ลง เช่น เราอาจจะใช้เครื่องในการตอบปัญหาที่ไม่ซับซ้อนยุ่งยากนัก เพื่อเป็นการเปิดเวลาให้มนุษย์จริงๆ เป็นผู้ตอบคำถามที่ซับซ้อน ส่วนงานที่ต้องอาศัยความคิดสร้างสรรค์ ความแปลกใหม่ เทคโนโลยีทางด้านปัญญาประดิษฐ์นั้นก็ยังด้อยกว่ามนุษย์อยู่มาก แต่ว่าเทคโนโลยีอาจจะมีส่วนช่วยในการสร้างแรงบันดาลใจให้ผู้ที่ทำงานในด้านงานสร้างสรรค์ได้พัฒนางานของตนต่อไป หรือนักแปลอาจจะใช้ปัญญาประดิษฐ์ในการแปลประโยคที่ง่ายๆ เพื่อเป็นการแบ่งเบาภาระ และให้เครื่องเป็นตัวช่วยแนะว่าประโยคใดมนุษย์นักแปลนั้นควรจะใส่ใจเป็นพิเศษเพื่อพัฒนาคุณภาพของการแปลโดยรวม ขณะนี้นักวิจัยจำนวนมากทั้งทางด้านภาษาศาสตร์และทางด้านวิทยาการคอมพิวเตอร์ได้ร่วมมือกันสรรค์สร้างและพัฒนาเทคโนโลยีใหม่ๆ ที่ทำให้เครื่องเข้าใจภาษาได้มากขึ้น เราในฐานะส่วนหนึ่งของประชาคมดิจิทัลควรติดตามข้อมูลทางด้านปัญญาประดิษฐ์ และทักษะทางด้านเทคโนโลยีอย่างสม่ำเสมอ และพิจารณาว่าเทคโนโลยีที่มีอยู่แล้ว และเทคโนโลยีที่กำลังจะมาในอนาคตนั้นสามารถนำมาประยุกต์ใช้เพื่อทำให้การงานของเราเองกินเวลาน้อยลง และเปิดเวลาให้เราพัฒนางานของเราในส่วนอื่นๆ ได้มากขึ้นหรือไม่ โดยไม่ต้องกลัวว่าวันหนึ่งหุ่นยนต์จะมีความคิดอ่านของตัวเองขึ้นมาและยึดครองโลก หรือทำให้คนเป็นล้านตกงานกันอย่างที่ใครหลายคนสะพรึงกลัวกัน ปัญญาประดิษฐ์ยังมีศักยภาพที่จะพัฒนาขึ้นไปได้อีกมาก แต่ปัญญาประดิษฐ์ที่ทำงานโดยเต็มศักยภาพนั้นยังเพียงเป็นภาพวาดในอนาคต
* บทความนี้ผู้เขียนใช้เครื่องถอดเสียงพูดเป็นตัวอักษรในการเขียนทั้งหมด
ที่มา :
เอกสารวิชาการ “STATE-OF-THE-ART SPEECH RECOGNITION WITH SEQUENCE-TO-SEQUENCE MODELS” โดย บริษัท Google (23 กุมภาพันธ์ 2018) จาก arxiv.org
เอกสารวิชาการ “QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension” (23 เมษายน 2018) จาก arxiv.org
เรื่อง : ดร.อรรถพล ธำรงรัตนฤทธิ์
หลักสูตร อ.บ. เทคโนโลยีภาษาและสารสนเทศ คณะอักษรศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย